
Šta je veliki jezički model (LLM): Objašnjenje
Nakon što je OpenAI lansirao ChatGPT 2022. godine, svet je doživeo nove tehnološke napretke, i čini se da ne postoji kraj ovom neprekidnom razvoju.

AI chatbotovi su lansirani od strane Google-a, Microsoft-a, Meta-e, Anthropic-a i mnogih drugih kompanija. Svi ovi chatbotovi su pokretani LLM-ovima (velikim jezičkim modelima). Ali šta tačno predstavlja veliki jezički model i kako on funkcioniše?

LLM (veliki jezički model) je vrsta veštačke inteligencije (AI) koja se trenira na velikom skupu tekstova. Dizajniran je da razume i generiše ljudski jezik na osnovu principa verovatnoće. U suštini, to je algoritam dubokog učenja. LLM može generisati eseje, pesme, članke i pisma; generisati kod; prevesti tekstove sa jednog jezika na drugi, sažeti tekstove i još mnogo toga. Što je veći skup podataka za treniranje, to su bolje sposobnosti prirodne obrade jezika (NLP) LLM-a. Generalno, istraživači AI-a smatraju da su LLM-ovi sa 2 milijarde ili više parametara “veliki” jezički modeli. Ako se pitate šta je parametar, to je broj promenljivih na kojima je model treniran. Što je veći broj parametara, to je model veći i ima više sposobnosti. Da vam damo primer, kada je OpenAI lansirao GPT-2 LLM 2019. godine, bio je treniran na 1,5 milijardi parametara. Kasnije, 2020. godine, GPT-3 je lansiran sa 175 milijardi parametara, preko 116 puta većim modelom. Najsavremeniji model GPT-4 ima 1,76 triliona parametara. Kao što možete videti, tokom vremena, broj parametara postaje sve veći, donoseći naprednije i složenije sposobnosti velikim jezičkim modelima.
Kako funkcionišu LLM-ovi: Proces treniranja
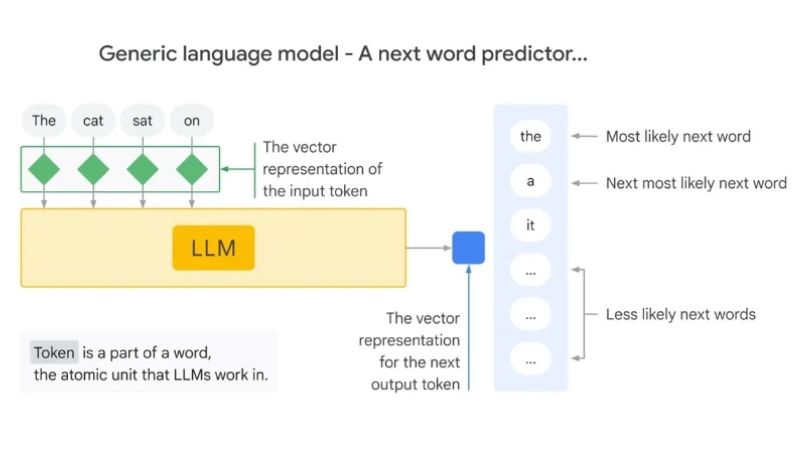
Jednostavno rečeno, LLM-ovi uče da predviđaju sledeću reč u rečenici. Ovaj proces učenja se naziva predtrening gde se model trenira na velikom korpusu teksta uključujući knjige, članke, vesti, obimne tekstualne podatke sa web sajtova, Wikipedije i više. U ovom predtrening procesu, model uči kako funkcioniše jezik, njegovu gramatiku, sintaksu, činjenice o svetu, sposobnosti rasuđivanja, obrasce i više. Kada se predtrening završi, model prolazi kroz proces fino podešavanja. Kao što možete zaključiti, fino podešavanje se radi na specifičnim skupovima podataka. Na primer, ako želite da LLM bude dobar u kodiranju, fino ga podešavate na obimnim skupovima podataka za kodiranje. Slično tome, ako želite da model bude dobar u kreativnom pisanju, trenirate LLM na velikom korpusu literarnog materijala, pesama itd.
Šta je Transformer arhitektura za LLM-ove?
Gotovo svi moderni LLM-ovi su izgrađeni na transformer arhitekturi, ali šta je to tačno? Ukratko ćemo proći kroz istoriju LLM-ova. U pre-transformer eri, postojalo je nekoliko arhitektura neuronskih mreža kao što su RNN (rekurentna neuronska mreža), CNN (konvolutivna neuronska mreža) i više. Međutim, 2017. godine, istraživači iz Google Brain tima objavili su seminalni rad pod nazivom “Attention is All You Need” (Vaswani, et al). Ovaj rad je uveo Transformer arhitekturu koja je sada postala temelj svih LLM-ova koji se bave zadacima prirodne obrade jezika. Osnovna ideja transformer arhitekture je samopažnja. Može paralelno procesuirati sve reči u rečenici, razumevajući kontekst i odnos između reči. Takođe omogućava efikasno treniranje jer otključava paralelizam. Nakon što je rad objavljen, Google je lansirao prvi LLM zasnovan na transformer arhitekturi pod nazivom BERT 2018. godine. Kasnije, OpenAI se pridružio i lansirao svoj prvi GPT-1 model na istoj arhitekturi.
Primene LLM-ova
Već znamo da LLM-ovi sada pokreću AI chatbotove kao što su ChatGPT, Gemini, Microsoft Copilot i više. Oni mogu izvršavati NLP zadatke uključujući generisanje teksta, prevođenje, sažimanje, generisanje koda, pisanje priča, pesama itd. LLM-ovi se takođe koriste za konverzacione asistente. Nedavno je OpenAI prikazao svoj GPT-4o model koji je izvanredan u vođenju razgovora. Pored toga, LLM-ovi se već testiraju za kreiranje AI agenata koji mogu obavljati zadatke za vas. I OpenAI i Google rade na tome da donesu AI agente u bliskoj budućnosti.
Sve u svemu, LLM-ovi se široko primenjuju kao chatboti za korisničku podršku i za generisanje sadržaja. Dok veliki jezički modeli rastu u popularnosti, istraživači mašinskog učenja veruju da je potreban još jedan proboj da bi se postigao AGI (opšta veštačka inteligencija) — AI sistem inteligentniji od ljudi.
Još nismo videli takve probojne razvoje u eri Generativne AI, međutim, neki istraživači veruju da treniranje mnogo većeg LLM-a može dovesti do određenog nivoa svesti u AI modelima.
Izvor: Beebom